810364804
- 浏览: 779477 次
-

文章分类
最新评论
-
06softwaregaojie:
能给个完整的例子吗,这篇文章里,很多多没有描述到 ,比如App ...
datatables的服务器分页
dom4j解析xml字符串实例
DOM4J
与利用DOM、SAX、JAXP机制来解析xml相比,DOM4J 表现更优秀,具有性能优异、功能强大和极端易用使用的特点,只要懂得DOM基本概念,就可以通过dom4j的api文档来解析xml。dom4j是一套开源的api。实际项目中,往往选择dom4j来作为解析xml的利器。
先来看看dom4j中对应XML的DOM树建立的继承关系
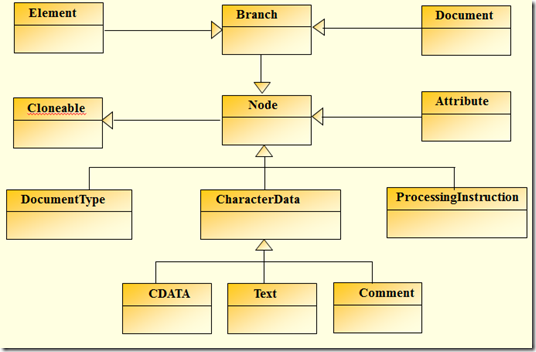
针对于XML标准定义,对应于图2-1列出的内容,dom4j提供了以下实现:
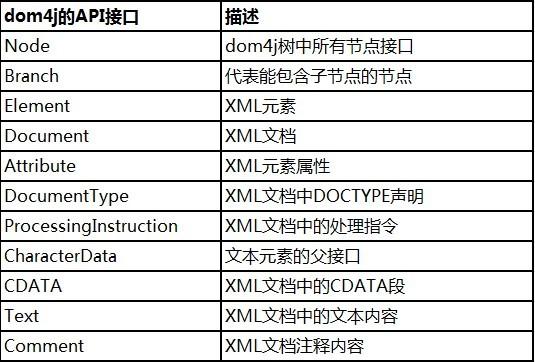
同时,dom4j的NodeType枚举实现了XML规范中定义的node类型。如此可以在遍历xml文档的时候通过常量来判断节点类型了。
常用API
class org.dom4j.io.SAXReader
- read 提供多种读取xml文件的方式,返回一个Domcument对象
interface org.dom4j.Document
- iterator 使用此法获取node
- getRootElement 获取根节点
interface org.dom4j.Node
- getName 获取node名字,例如获取根节点名称为bookstore
- getNodeType 获取node类型常量值,例如获取到bookstore类型为1——Element
- getNodeTypeName 获取node类型名称,例如获取到的bookstore类型名称为Element
interface org.dom4j.Element
- attributes 返回该元素的属性列表
- attributeValue 根据传入的属性名获取属性值
- elementIterator 返回包含子元素的迭代器
- elements 返回包含子元素的列表
interface org.dom4j.Attribute
- getName 获取属性名
- getValue 获取属性值
interface org.dom4j.Text
- getText 获取Text节点值
interface org.dom4j.CDATA
- getText 获取CDATA Section值
interface org.dom4j.Comment
- getText 获取注释
实例一:

1 //先加入dom4j.jar包 2 import java.util.HashMap; 3 import java.util.Iterator; 4 import java.util.Map; 5 6 import org.dom4j.Document; 7 import org.dom4j.DocumentException; 8 import org.dom4j.DocumentHelper; 9 import org.dom4j.Element; 10 11 /** 12 * @Title: TestDom4j.java 13 * @Package 14 * @Description: 解析xml字符串 15 * @author 无处不在 16 * @date 2012-11-20 下午05:14:05 17 * @version V1.0 18 */ 19 public class TestDom4j { 20 21 public void readStringXml(String xml) { 22 Document doc = null; 23 try { 24 25 // 读取并解析XML文档 26 // SAXReader就是一个管道,用一个流的方式,把xml文件读出来 27 // 28 // SAXReader reader = new SAXReader(); //User.hbm.xml表示你要解析的xml文档 29 // Document document = reader.read(new File("User.hbm.xml")); 30 // 下面的是通过解析xml字符串的 31 doc = DocumentHelper.parseText(xml); // 将字符串转为XML 32 33 Element rootElt = doc.getRootElement(); // 获取根节点 34 System.out.println("根节点:" + rootElt.getName()); // 拿到根节点的名称 35 36 Iterator iter = rootElt.elementIterator("head"); // 获取根节点下的子节点head 37 38 // 遍历head节点 39 while (iter.hasNext()) { 40 41 Element recordEle = (Element) iter.next(); 42 String title = recordEle.elementTextTrim("title"); // 拿到head节点下的子节点title值 43 System.out.println("title:" + title); 44 45 Iterator iters = recordEle.elementIterator("script"); // 获取子节点head下的子节点script 46 47 // 遍历Header节点下的Response节点 48 while (iters.hasNext()) { 49 50 Element itemEle = (Element) iters.next(); 51 52 String username = itemEle.elementTextTrim("username"); // 拿到head下的子节点script下的字节点username的值 53 String password = itemEle.elementTextTrim("password"); 54 55 System.out.println("username:" + username); 56 System.out.println("password:" + password); 57 } 58 } 59 Iterator iterss = rootElt.elementIterator("body"); ///获取根节点下的子节点body 60 // 遍历body节点 61 while (iterss.hasNext()) { 62 63 Element recordEless = (Element) iterss.next(); 64 String result = recordEless.elementTextTrim("result"); // 拿到body节点下的子节点result值 65 System.out.println("result:" + result); 66 67 Iterator itersElIterator = recordEless.elementIterator("form"); // 获取子节点body下的子节点form 68 // 遍历Header节点下的Response节点 69 while (itersElIterator.hasNext()) { 70 71 Element itemEle = (Element) itersElIterator.next(); 72 73 String banlce = itemEle.elementTextTrim("banlce"); // 拿到body下的子节点form下的字节点banlce的值 74 String subID = itemEle.elementTextTrim("subID"); 75 76 System.out.println("banlce:" + banlce); 77 System.out.println("subID:" + subID); 78 } 79 } 80 } catch (DocumentException e) { 81 e.printStackTrace(); 82 83 } catch (Exception e) { 84 e.printStackTrace(); 85 86 } 87 } 88 89 /** 90 * @description 将xml字符串转换成map 91 * @param xml 92 * @return Map 93 */ 94 public static Map readStringXmlOut(String xml) { 95 Map map = new HashMap(); 96 Document doc = null; 97 try { 98 // 将字符串转为XML 99 doc = DocumentHelper.parseText(xml); 100 // 获取根节点 101 Element rootElt = doc.getRootElement(); 102 // 拿到根节点的名称 103 System.out.println("根节点:" + rootElt.getName()); 104 105 // 获取根节点下的子节点head 106 Iterator iter = rootElt.elementIterator("head"); 107 // 遍历head节点 108 while (iter.hasNext()) { 109 110 Element recordEle = (Element) iter.next(); 111 // 拿到head节点下的子节点title值 112 String title = recordEle.elementTextTrim("title"); 113 System.out.println("title:" + title); 114 map.put("title", title); 115 // 获取子节点head下的子节点script 116 Iterator iters = recordEle.elementIterator("script"); 117 // 遍历Header节点下的Response节点 118 while (iters.hasNext()) { 119 Element itemEle = (Element) iters.next(); 120 // 拿到head下的子节点script下的字节点username的值 121 String username = itemEle.elementTextTrim("username"); 122 String password = itemEle.elementTextTrim("password"); 123 124 System.out.println("username:" + username); 125 System.out.println("password:" + password); 126 map.put("username", username); 127 map.put("password", password); 128 } 129 } 130 131 //获取根节点下的子节点body 132 Iterator iterss = rootElt.elementIterator("body"); 133 // 遍历body节点 134 while (iterss.hasNext()) { 135 Element recordEless = (Element) iterss.next(); 136 // 拿到body节点下的子节点result值 137 String result = recordEless.elementTextTrim("result"); 138 System.out.println("result:" + result); 139 // 获取子节点body下的子节点form 140 Iterator itersElIterator = recordEless.elementIterator("form"); 141 // 遍历Header节点下的Response节点 142 while (itersElIterator.hasNext()) { 143 Element itemEle = (Element) itersElIterator.next(); 144 // 拿到body下的子节点form下的字节点banlce的值 145 String banlce = itemEle.elementTextTrim("banlce"); 146 String subID = itemEle.elementTextTrim("subID"); 147 148 System.out.println("banlce:" + banlce); 149 System.out.println("subID:" + subID); 150 map.put("result", result); 151 map.put("banlce", banlce); 152 map.put("subID", subID); 153 } 154 } 155 } catch (DocumentException e) { 156 e.printStackTrace(); 157 } catch (Exception e) { 158 e.printStackTrace(); 159 } 160 return map; 161 } 162 163 public static void main(String[] args) { 164 165 // 下面是需要解析的xml字符串例子 166 String xmlString = "<html>" + "<head>" + "<title>dom4j解析一个例子</title>" 167 + "<script>" + "<username>yangrong</username>" 168 + "<password>123456</password>" + "</script>" + "</head>" 169 + "<body>" + "<result>0</result>" + "<form>" 170 + "<banlce>1000</banlce>" + "<subID>36242519880716</subID>" 171 + "</form>" + "</body>" + "</html>"; 172 173 /* 174 * Test2 test = new Test2(); test.readStringXml(xmlString); 175 */ 176 Map map = readStringXmlOut(xmlString); 177 Iterator iters = map.keySet().iterator(); 178 while (iters.hasNext()) { 179 String key = iters.next().toString(); // 拿到键 180 String val = map.get(key).toString(); // 拿到值 181 System.out.println(key + "=" + val); 182 } 183 } 184 185 }
实例二:
1 /** 2 * 解析包含有DB连接信息的XML文件 3 * 格式必须符合如下规范: 4 * 1. 最多三级,每级的node名称自定义; 5 * 2. 二级节点支持节点属性,属性将被视作子节点; 6 * 3. CDATA必须包含在节点中,不能单独出现。 7 * 8 * 示例1——三级显示: 9 * <db-connections> 10 * <connection> 11 * <name>DBTest</name> 12 * <jndi></jndi> 13 * <url> 14 * <![CDATA[jdbc:mysql://localhost:3306/db_test?useUnicode=true&characterEncoding=UTF8]]> 15 * </url> 16 * <driver>org.gjt.mm.mysql.Driver</driver> 17 * <user>test</user> 18 * <password>test2012</password> 19 * <max-active>10</max-active> 20 * <max-idle>10</max-idle> 21 * <min-idle>2</min-idle> 22 * <max-wait>10</max-wait> 23 * <validation-query>SELECT 1+1</validation-query> 24 * </connection> 25 * </db-connections> 26 * 27 * 示例2——节点属性: 28 * <bookstore> 29 * <book category="cooking"> 30 * <title lang="en">Everyday Italian</title> 31 * <author>Giada De Laurentiis</author> 32 * <year>2005</year> 33 * <price>30.00</price> 34 * </book> 35 * 36 * <book category="children" title="Harry Potter" author="J K. Rowling" year="2005" price="$29.9"/> 37 * </bookstore> 38 * 39 * @param configFile 40 * @return 41 * @throws Exception 42 */ 43 public static List<Map<String, String>> parseDBXML(String configFile) throws Exception { 44 List<Map<String, String>> dbConnections = new ArrayList<Map<String, String>>(); 45 InputStream is = Parser.class.getResourceAsStream(configFile); 46 SAXReader saxReader = new SAXReader(); 47 Document document = saxReader.read(is); 48 Element connections = document.getRootElement(); 49 50 Iterator<Element> rootIter = connections.elementIterator(); 51 while (rootIter.hasNext()) { 52 Element connection = rootIter.next(); 53 Iterator<Element> childIter = connection.elementIterator(); 54 Map<String, String> connectionInfo = new HashMap<String, String>(); 55 List<Attribute> attributes = connection.attributes(); 56 for (int i = 0; i < attributes.size(); ++i) { // 添加节点属性 57 connectionInfo.put(attributes.get(i).getName(), attributes.get(i).getValue()); 58 } 59 while (childIter.hasNext()) { // 添加子节点 60 Element attr = childIter.next(); 61 connectionInfo.put(attr.getName().trim(), attr.getText().trim()); 62 } 63 dbConnections.add(connectionInfo); 64 } 65 66 return dbConnections; 67 }
分享到:


发表评论

相关推荐
Java解析XML的四种方法 1. DOM生成和解析XML文档 2. SAX生成和解析XML文档 3. DOM4J生成和解析XML文档 4. JDOM生成和解析XML
三、使用dom4j解析xml文件 5 1. 构建dom4j树 5 2. 获取节点 5 3. 获取属性 6 4. 使用XPath获取节点和属性 6 四、使用dom4j修改xml文件 7 五、常用方法 8 1.Element元素API 8 2. Attribute属性API 8 2. 字符串转化 8...
实例4 删除字符串中的空白 实例5 字符串反转 实例6 字符串加密 实例7 检查日期的有效性 实例8 简单猜数游戏 实例9 验证信用卡号 实例10 计算两个数组并、交和差 实例11 数组排序 第2章 PHP文件实例 实例12 获取文件...
实例4 删除字符串中的空白 实例5 字符串反转 实例6 字符串加密 实例7 检查日期的有效性 实例8 简单猜数游戏 实例9 验证信用卡号 实例10 计算两个数组并、交和差 实例11 数组排序 第2章 PHP文件实例 实例12 ...
Dom4jHelper Java XML操作实例类,解析url xml文档,遍历解析文档,遍历解析元素,解析文件,获得根元素,修改xml某节点的值,输出文件路径及文件名 如果输出文件为null,则默认为原xml文件,xml转换为字符串,字符串转换为...
实例105 DOM4j解析XML文件 278 实例106 JDOM解析XML文件 285 实例107 DOM解析XML文件 292 实例108 SAX解析XML文件 297 实例109 W3C解析XML文件 301 第13章 Java网络编程 306 实例110 获取IP地址和域名 306 ...
% _ [abc1-9]格式字符串 * * @param format * 格式字符串 如:邮箱:%@%_ * @param value * 被判断的值 yiyongpeng@tom.com * @return 是否匹配 */ public boolean like(String format, String value){} ...
2.3.8 字符串 2.4 字符数据 2.5 属性 2.5.1 特殊属性 2.5.2 空白 2.5.3 行尾的处理 2.6 字符引用和实体引用 2.6.1 字符引用 2.6.2 实体引用 2.7 处理指令 2.8 注释 2.9 CDATA部分 2.10 文档结构 2.10.1...
5.3 使用DOM和XML的应用实例 5.3.1 简单的客户端实例 5.3.2 更复杂的编程实例 5.4 DOM和XML的未来 5.4.1 W3C的工作 5.4.2 应用 5.4.3 数据库、模式和DOM 5.5 小结 第6章 SAX 1.0: XML简易API 6.1 事件驱动...
5.3 使用DOM和XML的应用实例 5.3.1 简单的客户端实例 5.3.2 更复杂的编程实例 5.4 DOM和XML的未来 5.4.1 W3C的工作 5.4.2 应用 5.4.3 数据库、模式和DOM 5.5 小结 第6章 SAX 1.0: XML简易API 6.1 事件驱动...
5.3 使用DOM和XML的应用实例 5.3.1 简单的客户端实例 5.3.2 更复杂的编程实例 5.4 DOM和XML的未来 5.4.1 W3C的工作 5.4.2 应用 5.4.3 数据库、模式和DOM 5.5 小结 第6章 SAX 1.0: XML简易API 6.1 事件驱动...
5.3 使用DOM和XML的应用实例 125 5.3.1 简单的客户端实例 125 5.3.2 更复杂的编程实例 133 5.4 DOM和XML的未来 143 5.4.1 W3C的工作 143 5.4.2 应用 144 5.4.3 数据库、模式和DOM 144 5.5 小结 144 第6章 SAX 1.0: ...
分别是XML快速入门,XML的概念,XML的术语,XML的实现,XML的实例分析。最后附录介绍了XML的相关资源。作者站在普通网页设计人员的角度,用平实生动的语言,向您讲述XML的方方面面,帮助你拨开XML的神秘面纱,快速...
3_4.htm 替换字符串中的指定字符。 3_5.htm 将字符串分解为数组。 3_6.htm 字符串大小写的书写和判断。 第4章(\4) 示例描述:数组技术。 4_1.htm 创建空数组。 4_2.htm 创建带初始值的数组。 4_3....
StrRegExp.htm 使用正则表达式扩展字符串对象的方法 SpacilString.htm 使用特殊字符 StringClass.htm 字符类 quantifier.htm 量词 GroupBy.htm 分组 Reference.htm 反向引用 ChooseModel.htm 选择...
14.11.2 数字到字符串的变换 486 14.12 对输出元素排序 488 14.13 CDATA和<符 491 14.14 方式 493 14.15 使用xsl:variable定义常数 496 14.16 命名模板 496 14.16.1 参数 498 14.17 删除和保留空白 501 14.18 选择 ...