- жµПиІИ: 787543 жђ°
-

жЦЗзЂ†еИЖз±ї
з§ЊеМЇзЙИеЭЧ
- жИСзЪДиµДиЃѓ ( 0)
- жИСзЪДиЃЇеЭЫ ( 0)
- жИСзЪДйЧЃз≠Ф ( 0)
е≠Шж°£еИЖз±ї
- 2014-09 ( 35)
- 2014-08 ( 96)
- 2014-07 ( 111)
- жЫіе§Ъе≠Шж°£...
жЬАжЦ∞иѓДиЃЇ
-
06softwaregaojieпЉЪ
иГљзїЩдЄ™еЃМжХізЪДдЊЛе≠РеРЧпЉМињЩзѓЗжЦЗзЂ†йЗМпЉМеЊИе§Ъе§Ъж≤°жЬЙжППињ∞еИ∞ пЉМжѓФе¶ВApp ...
datatablesзЪДжЬНеК°еЩ®еИЖй°µ
JCR-170 java еЖЕеЃєдїУеЇУпЉИиљђиљљпЉЙ
иљђиљљиЗ™http://wrong1111.iteye.com/blog/186388
еОЯжЦЗеЬ∞еЭАпЉЪhttp://www.onjava.com/pub/a/onjava/2006/10/04/what-is-java-content-repository.html?page=4
JSR-170жККиЗ™еЈ±еЃЪдєЙдЄЇдЄАдЄ™иГљдЄОеЖЕеЃєдїУеЇУдЇТзЫЄиЃњйЧЃзЪДпЉМзЛђзЂЛзЪДпЉМж†ЗеЗЖзЪДжЦєеЉПгАВеРМжЧґеЃГдєЯеѓєеЖЕеЃєдїУеЇУеБЪеЗЇдЇЖиЗ™еЈ±зЪДеЃЪдєЙпЉМеЃГиЃ§дЄЇеЖЕеЃєдїУеЇУжШѓдЄАдЄ™йЂШзЇІзЪДдњ°жБѓзЃ°зРЖ з≥їзїЯпЉМиѓ•з≥їзїЯжШѓжШѓдЉ†зїЯзЪДжХ∞жНЃдїУеЇУзЪДжЙ©е±ХпЉМеЃГжПРдЊЫдЇЖиѓЄе¶ВзЙИжЬђжОІеИґгАБеЕ®жЦЗж£А糥пЉМиЃњйЧЃжОІеИґпЉМеЖЕеЃєеИЖз±їгАБиЃњйЧЃжОІеИґгАБеЖЕеЃєдЇЛдїґзЫСиІЖз≠ЙеЖЕеЃєжЬНеК°гАВ
Java Content Repository APIпЉИJSR-170пЉЙиѓХеЫЊеїЇзЂЛдЄАе•Чж†ЗеЗЖзЪДAPIеОїиЃњйЧЃеЖЕеЃєдїУеЇУгАВе¶ВжЮЬдљ†еѓєеЖЕеЃєзЃ°зРЖз≥їзїЯпЉИCMSпЉЙдЄНзЖЯжВЙзЪДиѓЭпЉМдљ†дЄАеЃЪдЉЪеѓєеЖЕеЃєдїУеЇУжШѓдїАдєИжДЯеИ∞зЦСжГСгАВдљ†еПѓ дї•ињЩж†ЈеОїзРЖиІ£пЉМжККеЖЕеЃєдїУеЇУзРЖиІ£дЄЇдЄАдЄ™зФ®жЭ•е≠ШеВ®жЦЗжЬђеТМдЇМињЫеИґжХ∞жНЃпЉИеЫЊзЙЗпЉМwordжЦЗж°£пЉМPDFз≠Йз≠ЙпЉЙзЪДжХ∞жНЃе≠ШеВ®еЇФзФ®з®ЛеЇПгАВдЄАдЄ™жШЊиСЧзЪДзЙєзВєжШѓдљ†дЄНзФ®еЕ≥ењГдљ†зЬЯж≠£ зЪДжХ∞жНЃеИ∞еЇХе≠ШеВ®еЬ®дїАдєИеЬ∞жЦєпЉМжШѓеЕ≥з≥їжХ∞жНЃеЇУпЉЯжШѓжЦЗдїґз≥їзїЯпЉЯињШжШѓXMLпЉЯдЄНдїЕдїЕжШѓжХ∞жНЃзЪДе≠ШеВ®еТМиѓїеПЦпЉМе§Іе§ЪжХ∞зЪДеЖЕеЃєдїУеЇУињШжПРдЊЫдЇЖжЫіеК†йЂШзЇІзЪДеКЯиГљпЉМдЊЛе¶ВиЃњйЧЃжОІеИґпЉМ жЯ•жЙЊпЉМзЙИжЬђжОІеИґпЉМйФБеЃЪеЖЕеЃєз≠Йз≠ЙгАВ
дЄАжЃµжЧґйЧідї•жЭ•еЄВеЬЇдЄКеЗЇзО∞дЇЖеРДдЄ™еОВеЃґеЉАеПСзЪДдЄНеРМзЪДCMSз≥їзїЯпЉМињЩдЇЫз≥їзїЯйГљеїЇзЂЛеЬ®дїЦдїђеРДиЗ™зЪДеЖЕеЃєдїУеЇУдєЛдЄКгАВ
йЧЃйҐШеЗЇзО∞дЇЖпЉМжѓПдЄ™CMSеЉАеПСеХЖйГљжПРдЊЫдЇЖдїЦдїђиЗ™еЈ±зЪДAPIжЭ•иЃњйЧЃеЖЕеЃєдїУеЇУгАВињЩеѓєеЇФзФ®з®ЛеЇПзЪДеЉАеПСиАЕеЄ¶жЭ•дЇЖеЫ∞жЙ∞пЉМеЫ†дЄЇдїЦдїђи¶Бе≠¶дє†дЄНеРМзЪДеЉАеПСеХЖжПРдЊЫзЪДAPIпЉМеРМжЧґпЉМдїЦдїђзЪДдї£з†БдєЯдЄОињЩдЇЫзЙєеЃЪзЪДAPIдЇІзФЯдЇЖзїСеЃЪгАВ
JSR-170ж≠£жШѓдЄЇиІ£еЖ≥ињЩдЄАйЧЃйҐШиАМеЗЇзО∞зЪДпЉМеЃГжПРдЊЫдЇЖдЄАе•Чж†ЗеЗЖзЪДAPIжЭ•иЃњйЧЃдїїдљХжХ∞жНЃдїУеЇУгАВйАЪињЗJSR-170пЉМдљ†еЉАеПСдї£з†БеП™йЬАи¶БеЉХзФ® javax.jcr.* ињЩдЇЫз±їеТМжО•еП£гАВеЃГйАВзФ®дЇОдїїдљХеЕЉеЃєJSR-170иІДиМГзЪДеЖЕеЃєдїУеЇУгАВ
жИСдїђе∞ЖйАЪињЗдЄАдЄ™дЊЛе≠РжЭ•йАРж≠•дЇЖиІ£JSR-170гАВ
дЄЇдїАдєИйЬАи¶Б Java Content Repository API
йЪПзЭАеРДдЄ™еОВеЃґеРДиЗ™зЪДеЖЕеЃєдїУеЇУеЃЮзО∞жХ∞йЗПзЪДеҐЮйХњпЉМдЇЇдїђиґКжЭ•иґКйЬАи¶БдЄАзїДйАЪзФ®зЪДзЉЦз®ЛжО•еП£жЭ•дљњзФ®ињЩдЇЫеЖЕеЃєдїУеЇУпЉМињЩе∞±жШѓJSR-170жЙАи¶БеБЪзЪДдЄЬи•њгАВеЃГжПРдЊЫдЄАзїДйАЪзФ®зЪД зЉЦз®ЛжО•еП£жЭ•ињЮжО•еЖЕеЃєдїУеЇУгАВдљ†еПѓдї•жККJSR-170зРЖиІ£дЄЇеТМJDBCз±їдЉЉзЪДAPIпЉМињЩж†Јдљ†еПѓдї•дЄНдЊЭиµЦдїїдљХеЕЈдљУзЪДеЖЕеЃєдїУеЇУеЃЮзО∞жЭ•еЉАеПСдљ†зЪДз®ЛеЇПгАВдљ†еПѓдї•зЫіжО•дљњзФ® жФѓжМБJSR-170зЪДеЖЕеЃєдїУеЇУпЉЫжИЦиАЕе¶ВжЮЬдЄАдЇЫеОВеЃґзЪДеЖЕеЃєдїУеЇУдЄНжФѓжМБJSR-170еИЩеПѓдї•йАЪињЗињЩдЇЫеОВеЃґжПРдЊЫзЪДJSR-170й©±еК®жЭ•еЃМжИРдїОJSR-170дЄОеОВ еЃґзЙєеЃЪзЪДеЖЕеЃєдїУеЇУзЪДиљђжНҐгАВ
дЄЛйЭҐињЩеЉ†еЫЊжППињ∞дЇЖдљњзФ®JSR-170еЉАеПСзЪДеЇФзФ®з≥їзїЯзЪДзїУжЮДгАВеЬ®иѓ•з≥їзїЯињРи°МзЪДжЧґеАЩпЉМеЃГеПѓдї•жУНдљЬеЖЕеЃєдїУеЇУ1пЉМ2пЉМ3дЄ≠зЪДдїїжДПдЄАдЄ™гАВеЬ®ињЩдЇЫеЖЕеЃєдїУеЇУељУдЄ≠пЉМеП™жЬЙ2 жШѓзЫіжО•жФѓжМБJSR-170зЪДпЉМеЙ©дЄЛзЪДдЄ§дЄ™йГљйЬАи¶БJSR-170й©±еК®жЭ•еТМеЇФзФ®з≥їзїЯдЇ§дЇТгАВж≥®жДПпЉЪдљ†зЪДеЇФзФ®з≥їзїЯеЃМеЕ®дЄНзФ®еЕ≥ењГдљ†зЪДжХ∞жНЃжШѓе¶ВдљХе≠ШеВ®зЪДгАВ1еПѓиГљдљњзФ®дЇЖ еЕ≥з≥їжХ∞жНЃеЇУжЭ•е≠ШеВ®пЉМиАМ2дљњзФ®дЇЖжЦЗдїґз≥їзїЯпЉМиЗ≥дЇОдЄКпЉМеЃГзФЪиЗ≥жЫіеЙНеНЂзЪДдљњзФ®дЇЖXMLгАВ
JSR-170 APIеѓєдЄНеРМзЪДдЇЇеСШжПРдЊЫдЇЖдЄНеРМзЪДе•ље§ДгАВ
вЧПеѓєдЇОеЉАеПСиАЕжЧ†йЬАдЇЖиІ£еОВеЃґзЪДдїУеЇУзЙєеЃЪзЪДAPIпЉМеП™и¶БеЕЉеЃєJSR-170е∞±еПѓдї•йАЪињЗJSR-170иЃњйЧЃеЕґдїУеЇУгАВ
вЧПеѓєдЇОдљњзФ®CMSзЪДеЕђеПЄеИЩжЧ†йЬАиК±иієиµДйЗСзФ®дЇОеЬ®дЄНеРМзІНз±їCMSзЪДеЖЕеЃєдїУеЇУдєЛйЧіињЫи°МиљђжНҐгАВ
вЧПеѓєдЇОCMSеОВеЃґпЉМжЧ†йЬАиЗ™еЈ±еЉАеПСеЖЕеЃєдїУеЇУпЉМиАМдЄУж≥®дЇОеЉАеПСCMSеЇФзФ®гАВ
JSR-170 жШѓињЩж†ЈеЃЪдєЙеЖЕеЃєдїУеЇУзЪДпЉМеЖЕеЃєдїУеЇУзФ±дЄАзїД workspaceпЉИеЈ•дљЬз©ЇйЧіпЉЙзїДжИРпЉМињЩдЇЫworkspaceйАЪеЄЄеЇФиѓ•еМЕеРЂзЫЄдЉЉзЪДеЖЕеЃєгАВдЄАдЄ™еЖЕеЃєдїУеЇУжЬЙдЄАдЄ™еИ∞е§ЪдЄ™ workspaceгАВжѓПдЄ™workspaceйГљжШѓдЄАдЄ™ж†СзКґзїУжЮДпЉМйГљжЬЙдЄАдЄ™еФѓдЄАзЪДж†Сж†єиКВзВєпЉИroot nodeпЉЙгАВж†СдЄКзЪДitemпЉИеЕГзі†пЉЙжИЦиАЕжШѓдЄ™nodeпЉИиКВзВєпЉЙжИЦиАЕжШѓдЄ™propertyпЉИе±ЮжАІпЉЙгАВжѓПдЄ™nodeйГљеПѓдї•жЬЙйЫґдЄ™еИ∞е§ЪдЄ™е≠РиКВзВєеТМйЫґдЄ™еИ∞е§ЪдЄ™е≠Ре±Ю жАІгАВеП™жЬЙж†єиКВзВєж≤°жЬЙзИґиКВзВєпЉМеЕґдљЩжЙАжЬЙзЪДиКВзВєйГљжЬЙдЄАдЄ™зИґиКВзВєгАВproperty дєЯењЕй°їжЬЙдЄАдЄ™зИґиКВзВєпЉМдљЖеЃГж≤°жЬЙе≠РиКВзВєжИЦжШѓе≠Ре±ЮжАІпЉМproperty
жШѓеПґе≠РеЕГзі†гАВpropertyжШѓзЬЯж≠£е≠ШеВ®жХ∞жНЃзЪДеЕГзі†гАВ
дЄЛеЫЊжППињ∞дЇЖдЄАдЄ™blogеЇФзФ®з®ЛеЇПзЪДеЖЕеЃєдїУеЇУж®°еЮЛгАВжѓПдЄ™root nodeпЉИж†єиКВзВєпЉЙзЪДе≠РиКВзВєйГљдї£и°®дЇЖдЄАдЄ™blogеЃЮдљУгАВдЄОињЩдЄ™blogеЃЮдљУжЬЙеЕ≥зЪДжХ∞жНЃйГље≠ШеВ®еЬ® bolgEntry иКВзВєзЪДе±ЮжАІйЗМпЉМеЕґдЄ≠дЄАдЄ™ blogAttachment property е≠ШеВ®дЇЖдЄАдЄ™дЇМињЫеИґеЫЊзЙЗжЦЗдїґгАВ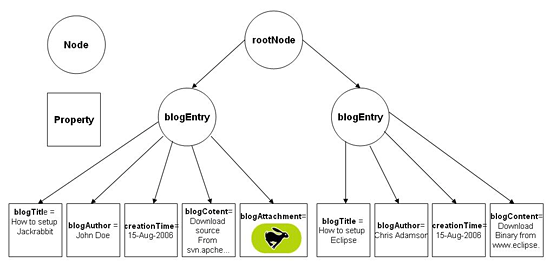
ж†єжНЃеЖЕеЃєдїУеЇУеЃЮзО∞зЪДеКЯиГљпЉМJSR-170еЃЪдєЙдЇЖдЄЙзІНзЇІеИЂпЉЪ
Level 1пЉЪеЃЪдєЙдЇЖдЄАдЄ™еП™иѓїзЪДеЖЕеЃєдїУеЇУгАВеКЯиГљеМЕжЛђиѓїеПЦеЖЕеЃєпЉМе∞ЖеЖЕеЃєеѓЉеЗЇдЄЇXMLеТМжЯ•жЙЊеЖЕеЃєгАВ
Level 2пЉЪеЃЪдєЙдЇЖеПѓеЖЩзЪДеЖЕеЃєдїУеЇУгАВLevel 2жШѓLevel 1зЪДжЙ©е±ХпЉМжЦ∞еҐЮзЪДеКЯиГљеМЕжЛђеЊАеЖЕеЃєдїУеЇУйЗМеЖЩеЕ•еЖЕеЃєпЉМеТМдїОXMLеѓЉеЕ•жХ∞жНЃеИ∞дїУеЇУгАВ
Advanced optionsпЉЪеЃЪдєЙеЃЮзО∞дЇФзІНйЩДеК†еКЯиГљпЉМзЙИжЬђжОІеИґгАБJTAгАБSQLжߕ胥гАБжЄЕжЩ∞зЪДеЖЕеЃєйФБеЃЪеТМзЫСиІЖгАВ
дїАдєИжШѓApache JackRabbitпЉЯ
Apache JackRabbitжШѓдЄАдЄ™еЉАжФЊжЇРз†БзЪДJSR-170 еЃЮзО∞пЉМеЃЮзО∞дЇЖLevel 2пЉМдљЖеЃГињШжЬЙиЃЄе§ЪжЙ©е±ХзЪДеКЯиГљгАВиѓ¶зїЖеПѓдї•еОїеЃГзЪДеЃШжЦєзљСзЂЩгАВ
дЄЛйЭҐжИСдїђеЖ≥еЃЪзФ®Apache JackRabbitжЭ•дљЬдЄЇжИСдїђз§ЇдЊЛз®ЛеЇПзЪДеЖЕеЃєдїУеЇУгАВ
е¶ВдљХйЕНзљЃApache JackRabbit
JackRabbitйЬАи¶БдЄ§дЄ™еПВжХ∞жЭ•йЕНзљЃдЄАдЄ™еЖЕеЃєдїУеЇУеЃЮдЊЛгАВ
1.еЖЕеЃєдїУеЇУдЄїзЫЃељХпЉЪињЩдЄ™жЦЗдїґзЫЃељХдЄЛйАЪеЄЄеМЕеРЂдЇЖжЙАжЬЙзЪДеЖЕеЃєпЉМжРЬ糥糥еЉХпЉМеЖЕйГ®йЕНзљЃжЦЗдїґеТМеЕґдїЦжМБдєЕеМЦдњ°жБѓгАВеЃГзЪДзїУжЮДзЬЛиµЈжЭ•дЉЪеГПдЄЛйЭҐињЩдЄ™ж†Је≠РпЉЪ
- c:/temp
- |
- |--Blogging
- |
- |-repository
- ||
- ||-index
- ||-meta
- ||-namespaces
- ||-nodetypes
- |
- |-version
- |
- |-workspace
- |
- |--default
еЬ®дЄКйЭҐзЪДжГЕеЖµдЄЛпЉМеЖЕеЃєдїУеЇУдЄїзЫЃељХжШѓc:/temp/Blogging.
2.еЖЕеЃєдїУеЇУйЕНзљЃжЦЗдїґпЉЪдЄАдЄ™еЕЄеЮЛзЪДйЕНзљЃжЦЗдїґе¶ВдЄЛпЉЪ
- <Repository>
- <FileSystemclass="org.apache.jackrabbit.core.fs.local.LocalFileSystem">
- <paramname="path"value="${rep.home}/repository"/>
- FileSystem>
- <SecurityappName="Jackrabbit">
- <AccessManagerclass="org.apache.jackrabbit.core.security.SimpleAccessManager"/>
- <LoginModuleclass="org.apache.jackrabbit.core.security.SimpleLoginModule">
- <paramname="anonymousId"value="anonymous"/>
- LoginModule>
- Security>
- <WorkspacesrootPath="${rep.home}/workspaces"defaultWorkspace="default"/>
- <Workspacename="${wsp.name}">
- <FileSystemclass="org.apache.jackrabbit.core.fs.local.LocalFileSystem">
- <paramname="path"value="${wsp.home}"/>
- FileSystem>
- <PersistenceManager
- class="org.apache.jackrabbit.core.state.db.DerbyPersistenceManager">
- <paramname="url"value="jdbc:derby:${wsp.home}/db;create=true"/>
- <paramname="schemaObjectPrefix"value="${wsp.name}_"/>
- PersistenceManager>
- <SearchIndexclass="org.apache.jackrabbit.core.query.lucene.SearchIndex">
- <paramname="path"value="${wsp.home}/index"/>
- SearchIndex>
- Workspace>
- <VersioningrootPath="${rep.home}/version">
- <FileSystemclass="org.apache.jackrabbit.core.fs.local.LocalFileSystem">
- <paramname="path"value="${rep.home}/version"/>
- FileSystem>
- <PersistenceManager
- class="org.apache.jackrabbit.core.state.db.DerbyPersistenceManager">
- <paramname="url"value="jdbc:derby:${rep.home}/version/db;create=true"/>
- <paramname="schemaObjectPrefix"value="version_"/>
- PersistenceManager>
- Versioning>
- <SearchIndexclass="org.apache.jackrabbit.core.query.lucene.SearchIndex">
- <paramname="path"value="${rep.home}/repository/index"/>
- SearchIndex>
- Repository>
еЬ®ињЩдЄ™йЕНзљЃжЦЗдїґйЗМпЉМеЕГзі†жШѓж†єеЕГзі†пЉМеЃГеМЕеРЂдЇЖдЄЛйЭҐињЩдЇЫеЕГзі†пЉЪ
aпЉМ: иѓ•еЕГзі†йЕНзљЃдЇЖеЖЕеЃєдїУеЇУзЪДеЕ®е±АжХ∞жНЃе≠ШеВ®дљНзљЃпЉМињЩдЇЫеЕ®е±АжХ∞жНЃеМЕжЛђеЈ≤ж≥®еЖМзЪДеСљеРНз©ЇйЧіпЉМеЃЪеИґзЪДиКВзВєз±їеЮЛз≠Йз≠ЙгАВ JackRabbit жПРдЊЫдЇЖеЗ†зІНйАЙжЛ©пЉМдЄАзІНжШѓеГПдЄКйЭҐдЊЛе≠РйЗМйЕНзљЃзЪДе≠ШеВ®еЬ®жЬђеЬ∞жЦЗдїґйЗМпЉМLocalFileSystem. е¶ВжЮЬдљ†жГ≥жККеЃГдїђе≠ШеВ®еЬ®жХ∞жНЃеЇУйЗМпЉМдљ†еПѓдї•дљњзФ® DbFileSystem.
bпЉМ:еЖЕеЃєдїУеЇУзЪДеЃЙеЕ®йЕНзљЃпЉМеЃГжЬЙдЄ§дЄ™е≠РеЕГзі†пЉЪеТМгАВйЕНзљЃзЪДз±їзФ®жЭ•еИ§жЦ≠зФ®жИЈжЬЙж≤°жЬЙжЭГйЩРжЭ•еѓєзЙєеЃЪжХ∞жНЃжЙІи°МзЙєеЃЪзЪДжУНдљЬгАВ
cпЉМ:ињЩдЄ™еЕГзі†зЪДйЕНзљЃеѓєжЙАжЬЙзЪДworkspaceйГљйАЪзФ®гАВеЃГзЪДrootPath е±ЮжАІжШѓжЙАжЬЙworkspaceжЦЗдїґе§єзЪДж†єзЫЃељХпЉМеЬ®жИСдїђзЪДдЊЛе≠РйЗМеЃГжШѓc:/temp/Blogging/WorkspaceпЉЫdefaultWorkspace е±ЮжАІеИЩеМЕеРЂдЇЖworkspaceзЪДйїШиЃ§еРНгАВ
dпЉМ:ињЩдЄ™еЕГзі†жШѓжЙАжЬЙworkspaceзЪДйїШиЃ§йЕНзљЃж®°жЭњгАВеОїжѓПдЄ™workspaceжЦЗдїґе§єдЄЛдљ†йГљдЉЪеПСзО∞дЄАдЄ™workspace.xmlжЦЗдїґпЉМињЩдЄ™жЦЗдїґеТМињЩдЄ™еЕГзі†зЪДйЕНзљЃдЄАж®°дЄАж†ЈгАВдЄЙдЄ™е≠РеЕГзі†пЉЪпЉМеТМињЩдЄ™workspaceзЫЄеЕ≥жХ∞жНЃзЪДе≠ШеВ®дљНзљЃпЉЫ пЉМињЩдЄ™workspaceеЖЕеЃєиКВзВєе≠ШеВ®з≠ЦзХ•пЉЫпЉМеПѓйАЙпЉМеЕ®жЦЗж£А糥гАВ
eпЉМ:йЕНзљЃдЄАдЄ™зЙИжЬђзЫЄеЕ≥зЪДеѓєи±°гАВеЕґеЃЮJackRabbitдєЯжШѓжККеЃГдљЬдЄЇиКВзВєжЭ•е§ДзРЖзЪДгАВ
ињЩдЄ§дЄ™еПВжХ∞еПѓдї•йАЪињЗдЄ§зІНжЦєеЉПиЃЊзљЃпЉМдЄАзІНжШѓеЬ®дїУеЇУеЃЮдЊЛеИЫеїЇжЧґзЫіжО•дЉ†еИ∞JackrabbitйЗМеОїпЉМдЄАзІНжШѓйЧіжО•зЪДйАЪињЗиЃЊзљЃJNDI object factoryгАВ
дљ†еПѓдї•иЃЊзљЃorg.apache.jackrabbit.repository.home ињЩдЄ™з≥їзїЯе±ЮжАІзЪДеАЉжЭ•жМЗеЃЪдљ†зЪДеЖЕеЃєдїУеЇУдЄїзЫЃељХпЉЫдєЯеПѓдї•иЃЊзљЃ
org.apache.jackrabbit.repository.conf ињЩдЄ™з≥їзїЯе±ЮжАІзЪДеАЉжЭ•жМЗеЃЪдљ†зЪДеЖЕеЃєдїУеЇУйЕНзљЃжЦЗдїґrepository.xmlгАВе¶ВжЮЬдљ†дЄНиЃЊеЃЪињЩдЄ§дЄ™
еПВжХ∞пЉМJackrabbitдЉЪжККељУеЙНзЫЃељХдљЬдЄЇеЖЕеЃєдїУеЇУдЄїзЫЃељХпЉМеРМжЧґпЉМеЃГжЬЙдЄАдЄ™йїШиЃ§зЪДеЖЕеЃєдїУеЇУйЕНзљЃжЦЗдїґгАВ
еЉАеПСжИСдїђзЪДдЊЛе≠Рз®ЛеЇП
jackrabbitеЈ≤зїПйЕНзљЃе•љдЇЖпЉМзО∞еЬ®иЃ©жИСдїђжЭ•еИЫеїЇжИСдїђзЪДз§ЇдЊЛз®ЛеЇПгАВињЩдЄ™дЊЛе≠Рз®ЛеЇПе∞Жи∞ГзФ®JCR-170APIгАВеЊИжШЊзДґпЉМжИСдїђйЬАи¶БеБЪдЄ§дїґдЇЛжГЕпЉЪдЄАдЄ™жШѓдљЬдЄЇеРОеП∞зЪДеѓєжХ∞жНЃињЫи°МеҐЮеИ†жФєжЯ•пЉИжМБдєЕе±ВпЉЙпЉМеП¶дЄАдЄ™жШѓеЉАеПСзЫЄеѓєеЇФзЪДUIзХМйЭҐпЉИWEB е±ВпЉЙгАВй¶ЦеЕИпЉМиЃ©жИСдїђеЃЪдєЙдЄАдЄ™DAOжО•еП£гАВињЩдЄ™жО•еП£BlogEntryDAO.java е¶ВдЄЛпЉЪ
- publicinterfaceBlogEntryDAO{
- publicvoidinsertBlogEntry(BlogEntryDTOblogEntryDTO)
- throwsBlogApplicationException;
- publicvoidupdateBlogEntry(BlogEntryDTOblogEntryDTO)
- throwsBlogApplicationException;
- publicArrayListgetBlogList()
- throwsBlogApplicationException;
- publicBlogEntryDTOgetBlogEntry(StringblogTitle)
- throwsBlogApplicationException;
- publicvoidremoveBlogEntry(StringblogTitle)
- throwsBlogApplicationException;
- publicArrayListsearchBlogList(StringuserName)
- throwsBlogApplicationException;
- publicvoidattachFileToBlogEntry(StringblogTitle,InputStreamuploadInputStream)
- throwsBlogApplicationException;
- publicInputStreamgetAttachedFile(StringblogTitle)
- throwsBlogApplicationException;
- }
ж≠£е¶Вдљ†зЬЛеИ∞зЪДпЉМињЩдЄ™жО•еП£жПРдЊЫдЇЖеҐЮеИ†жФєжЯ•зЪДжЦєж≥ХпЉМеРМжЧґињШжПРдЊЫдЇЖдЄ§дЄ™жЦєж≥ХжЭ•е§ДзРЖйЩДдїґгАВжО•дЄЛжЭ•пЉМжИСдїђйЬАи¶БдЄАдЄ™DTOеѓєи±°зФ®жЭ•еЬ®дЄ§дЄ™е±ВдєЛйЧідЉ†йАТжХ∞жНЃгАВ
- publicclassBlogEntryDTO{
- privateStringuserName;
- privateStringtitle;
- privateStringblogContent;
- privateCalendarcreationTime;
- //Getterandsettermethodsforeachoftheseproperties
- }
ињЩйЗМжИСдїђе∞ЖдїЕдїЕиЃ®иЃЇжМБдєЕе±ВгАВ
ињЮжО•jackrabbit
зО∞еЬ®пЉМзђђдЄАдїґдЇЛжГЕжШѓеЉАеПСдЄАдЄ™зїДдїґпЉМиОЈеЊЧдЄАдЄ™еИ∞jackrabbitеЖЕеЃєдїУеЇУзЪДињЮжО•гАВдЄЇдЇЖзЃАеНХпЉМжИСдїђе∞ЖеЬ®з®ЛеЇПеРѓеК®зЪДжЧґеАЩиОЈеЊЧињЩдЄ™ињЮжО•пЉМзДґеРОеЬ®з®ЛеЇПеБЬж≠ҐзЪДжЧґеАЩйЗКжФЊињЩдЄ™ињЮжО•гАВињЩйЗМжИСдїђдљњзФ®дЇЖStruts пЉМжЙАдї•жИСдїђйЬАи¶БеЉАеПСдЄАдЄ™PlugIn з±їгАВе¶ВдЄЛпЉЪ
- publicclassJackrabbitPluginimplementsPlugIn{
- publicstaticSessionsession;
- publicvoiddestroy(){
- session.logout();
- }
- publicvoidinit(ActionServletactionServlet,ModuleConfigmoduleConfig)
- throwsServletException{
- try{
- System.setProperty("org.apache.jackrabbit.repository.home",
- "c:/temp/Blogging");
- Repositoryrepository=newTransientRepository();
- session=repository.login(newSimpleCredentials("username",
- "password".toCharArray()));
- }catch(LoginExceptione){
- thrownewServletException(e);
- }catch(IOExceptione){
- thrownewServletException(e);
- }catch(RepositoryExceptione){
- thrownewServletException(e);
- }
- }
- publicstaticSessiongetSession(){
- returnsession;
- }
- }
init()жЦєж≥Хе∞ЖдЉЪеЬ®з®ЛеЇПеРѓеК®зЪДжЧґеАЩи∞ГзФ®пЉМdestroy()е∞ЖдЉЪеЬ®з®ЛеЇПеБЬж≠ҐзЪДжЧґеАЩи∞ГзФ®гАВжИСдїђеЬ®init()жЦєж≥ХйЗМиОЈеЊЧдЇЖеИ∞jackrabbit еЖЕеЃєдїУеЇУзЪДињЮжО•гАВзЬЛзЬЛдї£з†БпЉМжИСдїђеБЪзЪДзђђдЄАдїґдЇЛжШѓиЃЊеЃЪдЇЖorg.apache.jackrabbit.repository.homeињЩдЄ™з≥їзїЯе±ЮжАІпЉМеЬ®дЄКзѓЗ жЦЗзЂ†йЗМжПРеИ∞пЉМињЩдЄ™е±ЮжАІжШѓзФ®жЭ•жМЗеРСжИСдїђзЪДеЖЕеЃєдїУеЇУдЄїзЫЃељХгАВињЩйЗМжИСдїђиЃЊеЃЪеЃГдЄЇc:/temp/bloggingгАВжО•дЄЛжЭ•пЉМжИСдїђеИЫеїЇдЇЖ TransientRepositoryзЪДдЄАдЄ™еЃЮдЊЛгАВињЩжШѓjackrabbitжПРдЊЫзЪДз±їпЉМеЃГжПРдЊЫдЇЖдЄАдЄ™еИ∞еЖЕеЃєдїУеЇУзЪДдї£зРЖгАВеЃГеЬ®зђђдЄАдЄ™session
жЙУеЉАзЪДжЧґеАЩиЗ™еК®еРѓеК®еЖЕеЃєдїУеЇУпЉМеЬ®жЬАеРОдЄАдЄ™session еЕ≥йЧ≠зЪДжЧґеАЩиЗ™еК®еЕ≥йЧ≠еЖЕеЃєдїУеЇУгАВ
дЄАжЧ¶жИСдїђиОЈеЊЧдЇЖдЄАдЄ™еЖЕеЃєдїУеЇУеѓєи±°пЉМжИСдїђе∞±еПѓдї•и∞ГзФ®еЃГзЪДlogin() жЦєж≥ХжЭ•жЙУеЉАдЄАдЄ™ињЮжО•гАВlogin() жЦєж≥ХйЬАи¶БдЄАдЄ™Credential еѓєи±°дљЬдЄЇеПВжХ∞гАВе¶ВжЮЬCredential еѓєи±°жШѓNULLпЉМjackrabbitдЉЪиЃ§дЄЇеЕґдїЦзЪДжЬЇеИґеБЪдЇЖињЩдЄ™й™МиѓБпЉИжѓФе¶ВJAASпЉЙгАВlogin() жЦєж≥ХињШеПѓдї•дЉ†еЕ•дЄАдЄ™workspaceеРНе≠ЧдљЬдЄЇеПВжХ∞пЉМе¶ВжЮЬдЄНдЉ†еЕ•ињЩдЄ™еПВжХ∞пЉМjackrabbitдЉЪињФеЫЮдЄАдЄ™sessionеѓєи±°жМЗеРСйїШиЃ§зЪД workspaceгАВж≥®жДПworkspaceеТМsessionжШѓдЄАеѓєдЄАзЪДпЉМеН≥дЄАдЄ™sessionдїЕеѓєеЇФдЄАдЄ™workspaceгАВпЉИж≥®пЉЪе¶ВжЮЬдЄНдЉ†еЕ•
Credentialеѓєи±°пЉМињФеЫЮзЪДsessionеѓєworkspaceжШѓеП™иѓїзЪДпЉЙ
еҐЮеК†еЖЕеЃє
ињЮжО•еЈ≤зїПеїЇзЂЛиµЈжЭ•дЇЖпЉМдЄЛйЭҐиЃ©жИСдїђеЃЮзО∞BlogEntryDAOињЩдЄ™жО•еП£гАВзђђдЄАдЄ™жИСдїђжГ≥еЃЮзО∞зЪДжЦєж≥ХжШѓжПТеЕ•жХ∞жНЃ insertBlogEntry():
- publicvoidinsertBlogEntry(BlogEntryDTOblogEntryDTO)
- throwsBlogApplicationException{
- Sessionsession=JackrabbitPlugin.getSession();
- NoderootNode=session.getRootNode();
- NodeblogEntry=rootNode.addNode("blogEntry");
- blogEntry.setProperty("title",blogEntryDTO.getTitle());
- blogEntry.setProperty("blogContent",blogEntryDTO.getBlogContent());
- blogEntry.setProperty("creationTime",blogEntryDTO.getCreationTime());
- blogEntry.setProperty("userName",blogEntryDTO.getUserName());
- session.save();
- }
й¶ЦеЕИиОЈеЊЧsession еѓєи±°пЉМеН≥еИ∞еЖЕеЃєдїУеЇУзЙєеЃЪworkspaceзЪДињЮжО•гАВзДґеРОпЉМжИСдїђеЬ®ињЩдЄ™session еѓєи±°дЄКи∞ГзФ®getRootNode() жЦєж≥ХпЉМиОЈеЊЧињЩдЄ™workspaceзЪДж†єиКВзВєпЉМињЩдЄ™ж†єиКВзВєзЪДиЈѓеЊДжШѓпЉИ"/"пЉЙ.дЄАжЧ¶жИСдїђиОЈеЊЧињЩдЄ™ж†єиКВзВєпЉМжИСдїђе∞±еПѓдї•йАЪињЗaddNode()жЦєж≥ХеЬ®ињЩдЄ™ж†єиКВзВє дЄЛеҐЮеК†жЦ∞зЪДе≠РиКВзВєгАВжЦ∞иКВзВєзЪДеРНе≠ЧжШѓblogEntry. йАЪињЗsetProperty() жЦєж≥ХжИСдїђжККжХ∞жНЃе≠ШеВ®еИ∞иКВзВєзЪДpropertyйЗМгАВж≠£е¶ВжИСдїђеЕИеЙНиѓіжШОзЪДпЉМзЬЯеЃЮзЪДжХ∞жНЃжШѓе≠ШеВ®еЬ®propertyеЕГзі†йЗМпЉМpropertyеЕГзі†жШѓеПґе≠РгАВ
ж≥®жДПsession.save() ињЩи°Мдї£з†БгАВињЩдЄ™жЦєж≥ХжШѓењЕй°їи∞ГзФ®зЪДпЉМињЩдЄ™жЦєж≥Хи∞ГзФ®дєЛеЙНпЉМдїїдљХ Node,PropertyзЪДжФєеПШйÚ襀дњЭе≠ШеЬ®ињЩдЄ™sessionзЪДдЄАдЄ™дЄіжЧґеМЇеЯЯйЗМпЉМеЕґдїЦзЪДеТМиѓ•sessionињЮжО•еИ∞зЫЄеРМworkspaceзЪД sessionйГљзЬЛдЄНеИ∞ињЩдЇЫжФєеПШгАВељУињЩдЄ™жЦєж≥Х襀и∞ГзԮ庴襀жИРеКЯжЙІи°МеРОпЉМињЩдЇЫNode,PropertyзЪДжФєеПШжЙНдЉЪ襀жМБдєЕеМЦеИ∞ињЩдЄ™sessionеЕ≥иБФзЪД workspaceйЗМпЉМеРМжЧґжЙАжЬЙдЄОињЩдЄ™workspaceеЕ≥иБФзЪДsessionжЙНеПѓиІБињЩдЇЫеПШеМЦгАВзЫЄеѓєеЇФзЪДпЉМSession.refresh(false) е∞ЖдЉЪдЄҐеЉГжЙАжЬЙињЩдЇЫжФєеПШгАВitem.save()еТМItem.refresh(false)дљЬзФ®зЫЄдЉЉпЉМеП™жШѓељ±еУНиМГеЫійЩРеЃЪеЬ®еНХдЄ™ItemдЄКпЉИж≥®жДПпЉМеМЕжЛђеЃГзЪДе≠Р
иКВзВєпЉЙ
иОЈеЊЧеИЧи°®
еЬ®дЄКдЄАж≠•дЄ≠жИСдїђеЈ≤зїПжККжХ∞жНЃдњЭе≠ШеИ∞дЇЖеЖЕеЃєдїУеЇУдЄ≠пЉМйВ£жИСдїђе¶ВдљХз°ЃеЃЪжХ∞жНЃз°ЃеЃЮдњЭе≠ШињЫеОїдЇЖеСҐпЉЯgetBlogList() ињЩдЄ™жЦєж≥Хе∞ЖињФеЫЮж†єиКВзВєдЄЛжЙАжЬЙеРНдЄЇblogEntry.зЪДе≠РиКВзВєгАВ
- publicArrayListgetBlogList()throwsBlogApplicationException{
- Sessionsession=JackrabbitPlugin.getSession();
- ArrayListblogEntryList=newArrayList();
- NoderootNode=session.getRootNode();
- NodeIteratorblogEntryNodeIterator=rootNode.getNodes();
- while(blogEntryNodeIterator.hasNext()){
- NodeblogEntry=blogEntryNodeIterator.nextNode();
- if(blogEntry.getName().equals("blogEntry")==false)
- continue;
- Stringtitle=blogEntry.getProperty("title").getString();
- StringblogContent=blogEntry.getProperty("blogContent").getString();
- ValuecreationTimeValue=(Value)blogEntry.getProperty(
- "creationTime").getValue();
- StringuserName=blogEntry.getProperty("userName").getString();
- BlogEntryDTOblogEntryDTO=newBlogEntryDTO(userName,title,
- blogContent,creationTimeValue.getDate());
- blogEntryList.add(blogEntryDTO);
- }
- returnblogEntryList;
- }
дЄАжЧ¶дљ†иОЈеЊЧдЇЖж†єиКВзВєињЩдЄ™еѓєи±°пЉМдљ†е∞±еПѓдї•йАЪињЗи∞ГзФ®getNodes()ињЩдЄ™жЦєж≥ХжЭ•иОЈеПЦеЃГжЙАжЬЙзЪДе≠РиКВзВєгАВе¶ВжЮЬињЩдЄ™иКВзВєж≤°жЬЙе≠РиКВзВєпЉМе∞ЖињФеЫЮдЄАдЄ™з©ЇзЪД NodeIterator еѓєи±°гАВжИСдїђеПѓдї•йБНеОЖињЩдЄ™NodeIterator еѓєи±°жЭ•иОЈеЊЧеРНдЄЇblogEntry зЪДиКВзВєйЫЖеРИпЉМзДґеРОйАЪињЗgetProperty()жЦєж≥ХжЭ•иОЈеЊЧиКВзВєдЄКзЪДе±ЮжАІпЉМеН≥жИСдїђдњЭе≠ШзЪДзЬЯеЃЮжХ∞жНЃгАВgetProperty()жЦєж≥ХињФеЫЮValueеѓєи±°зЪДдЄА дЄ™еЃЮдЊЛгАВеЫ†дЄЇе≠ШеВ®жХ∞жНЃз±їеЮЛзЪДдЄНеРМпЉМжЙАдї•ињФеЫЮзЪДValueеѓєи±°еЃЮдЊЛжШѓдЄНеРМзЪДгАВж†єжНЃдЄНеРМзЪДжХ∞жНЃз±їеЮЛпЉМдљ†еЇФиѓ•и∞ГзФ®зЙєеЃЪзЪДжЦєж≥ХжЭ•иОЈеПЦжХ∞жНЃпЉМжѓФе¶В
getString()жЭ•иОЈеПЦе≠Чзђ¶дЄ≤пЉМиАМgetDate()иОЈеЊЧдЄАдЄ™жЧ•жЬЯгАВ
жЯ•жЙЊеЖЕеЃєпЉИзФ®XPathзЪДжЦєеЉПпЉЙ
JSR-170еЃЪдєЙдЇЖдЄ§зІНжЦєеЉПжЭ•жЯ•жЙЊеЖЕеЃєпЉИдєЯеПѓдї•зРЖиІ£дЄЇжЯ•жЙЊиКВзВєпЉЙгАВдЄАзІНдљњзФ®XPathиѓ≠ж≥ХпЉМеП¶дЄАзІНдљњзФ®SQLиѓ≠ж≥ХгАВJSR-170и¶Бж±ВLevel 1ењЕй°їеЃЮзО∞XPathзЪДжЦєеЉПпЉМиАМSQLзЪДжЦєеЉПеИЩдљЬдЄЇдЄАдЄ™еПѓйАЙзЪДеКЯиГљгАВ
XPathеОЯжЬђжШѓдЄАзІНиЃЊиЃ°зФ®жЭ•жЯ•жЙЊXMLеЕГзі†зЪДиѓ≠и®АгАВеЫ†дЄЇжИСдїђзЪДworkspaceжШѓж†СзКґзЪДзїУжЮДпЉМеЊИеГПXMLгАВжЙАдї•XPathиѓ≠ж≥ХйЭЮеЄЄйАВеРИдЇОеЬ®ињЩйЗМжЯ•жЙЊеЖЕеЃєгАВдЄЛйЭҐзЪДдї£з†БжЉФз§ЇдЇЖйАЪињЗдљЬиАЕеРНжЭ•жЯ•жЙЊиКВзВєгАВ
- Sessionsession=JackrabbitPlugin.getSession();
- WorkspaceworkSpace=session.getWorkspace();
- QueryManagerqueryManager=workSpace.getQueryManager();
- StringBufferqueryStr=newStringBuffer(
- "//blogEntry[@"+PROP_BLOGAUTHOR+"='");
- queryStr.append(userName);
- queryStr.append("']");
- Queryquery=queryManager.createQuery(queryStr.toString(),
- Query.XPATH);
- QueryResultqueryResult=query.execute();
- NodeIteratorqueryResultNodeIterator=queryResult.getNodes();
- while(queryResultNodeIterator.hasNext()){
- NodeblogEntry=queryResultNodeIterator.nextNode();
- Stringtitle=blogEntry.getProperty(PROP_TITLE).getString();
- StringblogContent=blogEntry.getProperty(PROP_BLOGCONTENT).getString();
- ValuecreationTimeValue=(Value)blogEntry.getProperty(
- PROP_CREATIONTIME).getValue();
- BlogEntryDTOblogEntryDTO=newBlogEntryDTO(userName,title,
- blogContent,creationTimeValue.getDate());
- blogEntryList.add(blogEntryDTO);
- }
- publicvoidattachFileToBlogEntry(StringblogTitle,
- InputStreamuploadInputStream)throwsBlogApplicationException{
- Sessionsession=JackrabbitPlugin.getSession();
- NodeblogEntryNode=getBlogEntryNode(blogTitle,session);
- blogEntryNode.setProperty(PROP_ATTACHMENT,uploadInputStream);
- session.save();
- }
- publicInputStreamgetAttachedFile(StringblogTitle)throwsBlogApplicationException{
- InputStreamattachFileIS=null;
- NodeblogEntryNode=getBlogEntryNode(blogTitle);
- ValueattachFileValue=(Value)blogEntryNode.getProperty(PROP_ATTACHMENT).getValue();
- attachFileIS=attachFileValue.getStream();
- returnattachFileIS;
- }
жАїзїУ
еИ∞ињЩйЗМпЉМжИСдїђеѓє JSR-170, Jackrabbitдї•еПКе¶ВдљХдљњзФ® JSR-170 APIеЉАеПСдЄАдЄ™зЃАеНХзЪДеЇФзФ®з®ЛеЇПйГљжЬЙдЇЖе§Іж¶ВзЪДдЇЖиІ£гАВжИСдїђзЪДиЃ®иЃЇжЫіе§ЪзЪДеЬ®дЇОеЯЇз°АгАВзЫЄдњ°е§ІеЃґдЄАеЃЪдЉЪеѓєеЖЕеЃєдїУеЇУжЬЙдЄ™еИЭж≠•зЪДиЃ§иѓЖгАВ


- 2013-12-13 14:49
- жµПиІИ 447
- иѓДиЃЇ(0)
- жЯ•зЬЛжЫіе§Ъ
еПСи°®иѓДиЃЇ

зЫЄеЕ≥жО®иНР
JSR-170 API jcr-1.0.jar
2003-2008-JCR-SCI ељ±еУНеЫ†е≠Р еМЕеРЂжЬАжЦ∞зЪДпЉИ2009-6-20пЉЙзЪДељ±еУНеЫ†е≠Ри°®
jackrabbit-jcr-servlet-1.5.2.jar
jackrabbit-jcr-server-1.5.2.jar
JCR-2.0.JARJCR-2.0.JARJCR-2.0.JARJCR-2.0.JARJCR-2.0.JARJCR-2.0.JARJCR-2.0.JARJCR-2.0.JARJCR-2.0.JARJCR-2.0.JARJCR-2.0.JARJCR-2.0.JARJCR-2.0.JAR
ж†Зз≠Њ:abdera-jcr-1.0.jar,abdera,jcr,1.0,jarеМЕдЄЛиљљ,дЊЭиµЦеМЕ
atlas-jcr-1.0.0.jar
ж†Зз≠Њ:abdera-jcr-0.4.0-incubating.jar,abdera,jcr,0.4.0,incubating,jarеМЕдЄЛиљљ,дЊЭиµЦеМЕ
ж†Зз≠Њ:abdera-jcr-1.1.3-sources.jar,abdera,jcr,1.1.3,sources,jarеМЕдЄЛиљљ,дЊЭиµЦеМЕ
ж†Зз≠Њ:abdera-jcr-0.4.0-incubating-sources.jar,abdera,jcr,0.4.0,incubating,sources,jarеМЕдЄЛиљљ,дЊЭиµЦеМЕ
2022SCISSCIеПКJCR-жХ∞жНЃеЇУдљњзФ®дїЛзїН-WEB-OF-SCIENCE-еЯєиЃ≠иѓЊдїґз≤ЊйАЙppt.ppt
ж†Зз≠Њ:abdera-jcr-1.1-sources.jar,abdera,jcr,1.1,sources,jarеМЕдЄЛиљљ,дЊЭиµЦеМЕ
ж†Зз≠Њ:abdera-jcr-1.1.2-sources.jar,abdera,jcr,1.1.2,sources,jarеМЕдЄЛиљљ,дЊЭиµЦеМЕ
ж†Зз≠Њ:abdera-jcr-1.0-sources.jar,abdera,jcr,1.0,sources,jarеМЕдЄЛиљљ,дЊЭиµЦеМЕ
ж†Зз≠Њ:abdera-jcr-1.1.1-sources.jar,abdera,jcr,1.1.1,sources,jarеМЕдЄЛиљљ,дЊЭиµЦеМЕ
ж†Зз≠Њ:abdera-jcr-1.1.3.jar,abdera,jcr,1.1.3,jarеМЕдЄЛиљљ,дЊЭиµЦеМЕ
ж†Зз≠Њ:abdera-jcr-1.1.1.jar,abdera,jcr,1.1.1,jarеМЕдЄЛиљљ,дЊЭиµЦеМЕ
ж†Зз≠Њ:abdera-jcr-1.1.2.jar,abdera,jcr,1.1.2,jarеМЕдЄЛиљљ,дЊЭиµЦеМЕ
JCR-зІСжКАжЬЯеИКиѓДдїЈпЉМеѓєдЇОеєње§ІеЬ®иѓїеНЪе£ЂжКХз®ње≠¶жЬѓиЃЇжЦЗжЬЙеЊИйЗНи¶БзЪДеЄЃеК©пЉМиѓЈе§ІеЃґдЄАиµЈеЕ±еЛЙпЉБ
ињЩжШѓдЄАзІНдљњзФ®Javaдї£з†БеИЫеїЇеТМжЙІи°МJCRжߕ胥зЪДжЦєж≥ХпЉМдљњзФ®зЪДжО•еП£еПЧHibernate / JPAдљњзФ®зЪДCriteria APIзЪДеРѓеПСгАВ иѓ•дї£з†БеЯЇдЇОOpenmindеЉАеПСзЪДзЪД пЉИopenutils-mgnlcriteriaпЉЙж®°еЭЧгАВ зЫЄиЊГдЇОopenutils-mgnlcriteriaе≠ШеЬ®дЇОдїїдљХ...